[ML기초세션]_2주차
세션 전 학습 내용
교재: ~p.111
[1-1] 인공지능과 머신러닝, 딥러닝
핵심 키워드: 인공지능, 머신러닝, 딥러닝
인공지능: 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
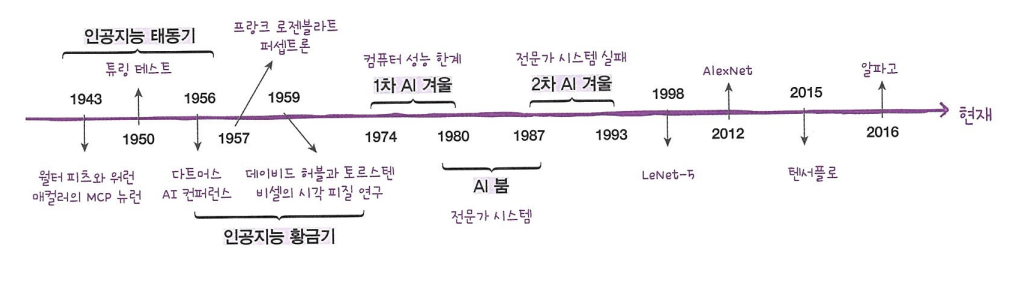
인공지능의 발전과정:
머신러닝: 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
머신러닝은 통계학과 컴퓨터 과학 분야와 밀접한 관계가 있다. 대표적으로, 통계 소프트웨어인 R에 다양한 ML 알고리즘이 구현됨.
최근에는 컴퓨터과학 분야가 ML의 발전을 주도하고 있다. 컴퓨터 과학 분야의 대표적인 ML 라이브러리는 사이킷런(scikit-learn)이다.
사이킷런 라이브러리는 파이썬 API를 사용하여 편리하다.
- 딥러닝: 많은 ML 알고리즘 중 인공 신경망을 기반으로 한 방법들을 통칭
파이썬 API를 제공하는 딥러닝 라이브러리로 구글은 TensorFlow를, 페이스북은 PyTorch를 발표했다.
[1-2] 코랩과 주피터 노트북
핵심 키워드: 코랩, 노트북, 구글 드라이브
네트워크에 연결된 컴퓨터와 구글 계정만 있다면 누구나 코랩에서 쉽게 머신러닝을 실습할 수 있다. (클라우드 기반 주피터 노트북 개발환경)
- 셀: 코랩에서 실행할 수 있는 최소 단위. 텍스트셀과 코드셀이 있다.
텍스트셀에선 HTML과 Markdown을 혼용할 수 있다.
- 노트북: 코랩의 프로그램 작성 단위. 대화식으로 프로그램을 만들 수 있어 데이터 분석이나 교육에 적합. 코드, 코드의 실행결과, 문서를 모두 저장할 수 있다.
[1-3] 마켓과 머신러닝
핵심 키워드: 특성, 훈련, k-최근접 이웃 알고리즘, 모델, 정확도
일반적인 프로그램은 누군가 정해준 기준대로 일을 하지만 머신러닝은 누구도 알려주지 않은 기준을 직접 찾아서 일한다. (도미 예시)
- 산점도: x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법이다.
1
import matplotlib.pyplot as plt
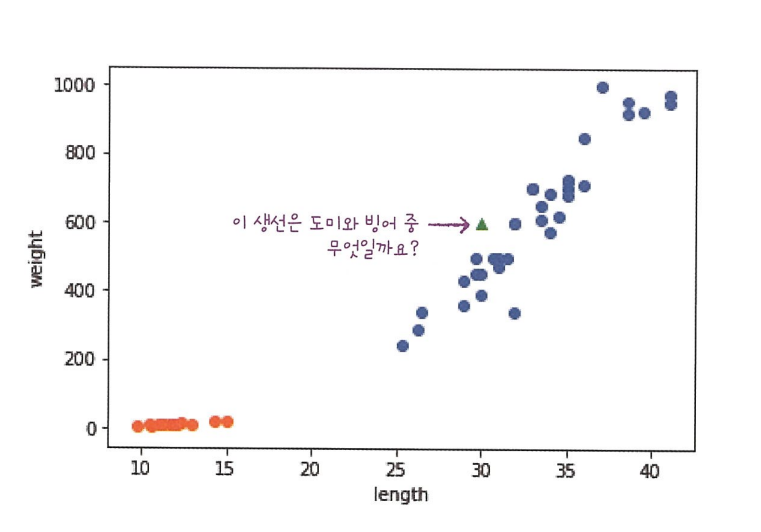
k-nearest neighbor 알고리즘을 위해 필요한 것은 데이터가 전부다. 새로운 데이터에 대해 예측할 때는 가장 가까운 직선거리에 어떤 데이터가 있는지만 살피면 된다. 단점은 이런 특징 때문에 데이터가 아주 많은 경우에는 사용이 어렵다. 데이터가 커지기에 메모리도 많이 필요하고 직선거리 계산에도 많은 시간이 필요하다. 가까운 몇 개의 데이터를 참고할지는 정하기 나름이다. KNeighborsClassifier의 기본값은 5다.
특성(feature): 데이터를 표현하는 하나의 성질 ex) 생선의 길이, 무게
훈련: ML 알고리즘이 데이터에서 규칙을 찾는 과정, 사이킷런에선 fit() method가 수행
k-nn 알고리즘: 가장 간단한 ML 알고리즘 중 하나. 어떤 규칙을 찾기보다는 전체 데이터를 메모리에 가지고 있는 것이 전부다.
핵심 패키지와 함수
matplotlib
- scatter(): 산점도를 그리는 함수, 2개 파라미터로 x,y값 전달. c 파라미터로 색깔도 지정가능!
scikit-learn
- KNeighborsClassifier(): k-최근접 이웃 분류 모델을 만드는 scikit-learn class
- fit(): 사이킷런 모델을 훈련할 때 사용하는 method. 두 파라미터로 훈련에 사용할 특성과 정답 데이터를 전달.
- predict(): 사이킷런 모델을 훈련하고 예측할 때 사용하는 method. 특성 데이터 하나만 매개변수로 받는다.
- score(): 훈련된 사이킷런 모델의 성능 측정. 두 파라미터로 특성과 정답 데이터 전달. 먼저 predict() method로 예측을 수행하고, 분류 모델일 경우 정답과 비교하여 올바르게 예측한 개수의 비율을 반환한다.
[2-1] 훈련 세트와 테스트 세트
핵심 키워드: 지도 학습, 비지도 학습, 훈련 세트, 테스트 세트
내게 있는 데이터 중 일부는 training set, 또 다른 일부는 test set으로 미리 구분해두고 supervised learning을 수행해야 한다. 전체 데이터의 20-30%를 test set으로 사용하는 경우가 많다.
샘플링 편향: training set과 test set에 샘플이 골고루 섞여있지 않아 샘플링이 한쪽으로 치우친 현상
넘파이(numpy): 파이썬의 대표적인 array 라이브러리. 고차원의 배열을 손쉽게 만들고 조작할 수 있는 간편한 도구를 많이 제공한다.
1
2
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
위의 코드를 이용하면 손쉽게 파이썬 리스트를 넘파이 배열로 바꿀 수 있다.
numpy의 array 객체는 배열의 크기를 알려주는 shape 속성을 제공한다.
print(input_arr.shape)로 (샘플 수, 특성 수)를 확인할 수 있다.사이킷런은 입출력 데이터가 numpy의 array다. -> 행과 열을 가지런히 출력함. 행-샘플, 열-특성
Tip! : training set의 값과 target이 함께 움직여야 하는데 이 array를 직접 섞기 보다는 array의 index를 랜덤하게(e.g. shuffle함수 이용) 섞는 편이 간단하다.
핵심 패키지와 함수
numpy
- seed(): 넘파이에서 난수를 생성하기 위한 정수 초깃값을 지정한다. 초깃값이 같으면 동일한 난수를 뽑을 수 있다.
- arange(): 일정한 간격의 정수 또는 실수 배열을 만든다. 파라미터는 1개면 종료 숫자를, 2개면 시작과 종료를, 3개면 시작, 종료, 간격을 의미한다.
- shuffle(): 주어진 배열을 랜덤하게 섞는다. 다차원 배열일 경우 첫 번째 축에 대해서만 섞는다.
[2-2] 데이터 전처리
핵심 키워드: 데이터 전처리, 표준점수, 브로드캐스팅
1
2
import numpy as np
np.column_stack(([1,2,3],[4,5,6]))
위의 코드처럼 column_stack() 함수를 수행하면 전달받은 리스트를 일렬로 세운 뒤 차례대로 나란히 연결한다. 즉, 위의 경우엔 array([1,4], [2,5], [3,6])을 열을 맞추어 반환한다.
튜플은 리스트와 매우 비슷하고, 원소에 순서가 있지만 한 번 만들어진 튜플은 수정할 수 없다. 튜플을 사용하면 함수로 전달한 값이 바뀌지 않는다는 것을 믿을 수 있기에 매개변수 값으로 많이 사용한다.
np.ones(),np.zeros()함수는 각각 원하는 개수의 1과 0을 채운 배열을 만들어준다. (e.g.,print(np.ones(5))-> [1. 1. 1. 1. 1.] )np.column_stack()함수는 두 배열을 2차원으로,np.concatenate()함수는 두 배열을 1차원으로 연결함.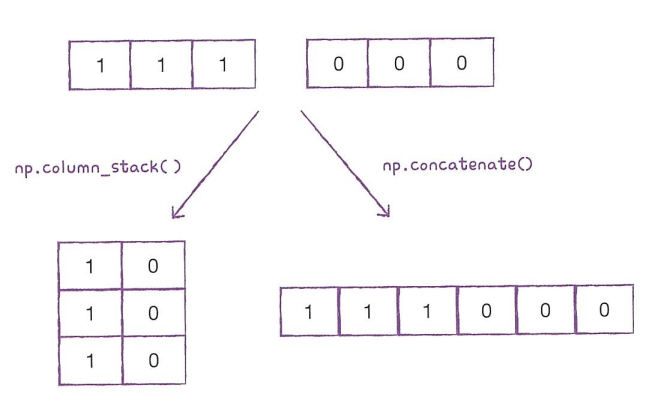
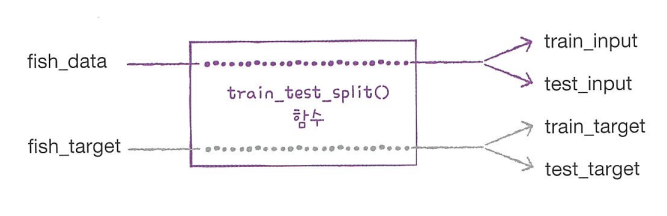
사이킷런에서는 training set와 test set을 손쉽게 나누어주는 train_test_split() 함수도 제공한다. 이 함수는 전달되는 리스트나 배열을 섞고 비율에 맞게 training set과 test set으로 나누어준다. 기본적으로는 25%를 테스트 셋으로 떼어 낸다.
train_test_split()함수 사용법1 2
from sklearn.model_selection import train_test_split train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state=42)
무작위로 데이터를 나누었을 때 샘플이 골고루 섞이지 않을 수 있다. 특히 일부 클래스의 개수가 적을 때 이런 일이 생길 수 있다.
train_test_split() 함수에서 stratify 매개변수에 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나누어준다.
데이터 전처리: ML모델에 training set을 주입하기 전, 데이터를 가공하는 단계
표준점수: 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다. training set의 스케일을 바꾸는 대표적인 방법 중 하나.
표준편차를 구하기 위한 과정은 아래와 같다.
1
2
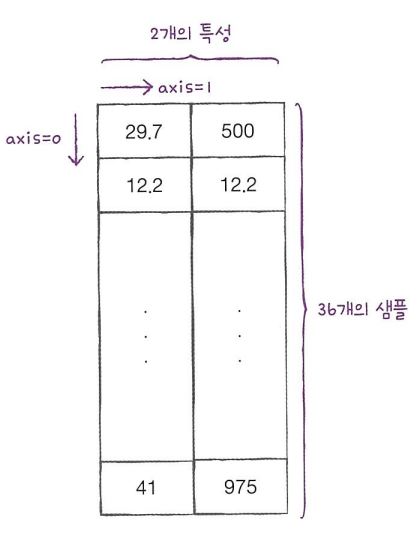
mean = np.mean(tain_input, axis=0)
std = np.std(train_input, axis=0)
- axis 설정 참조:
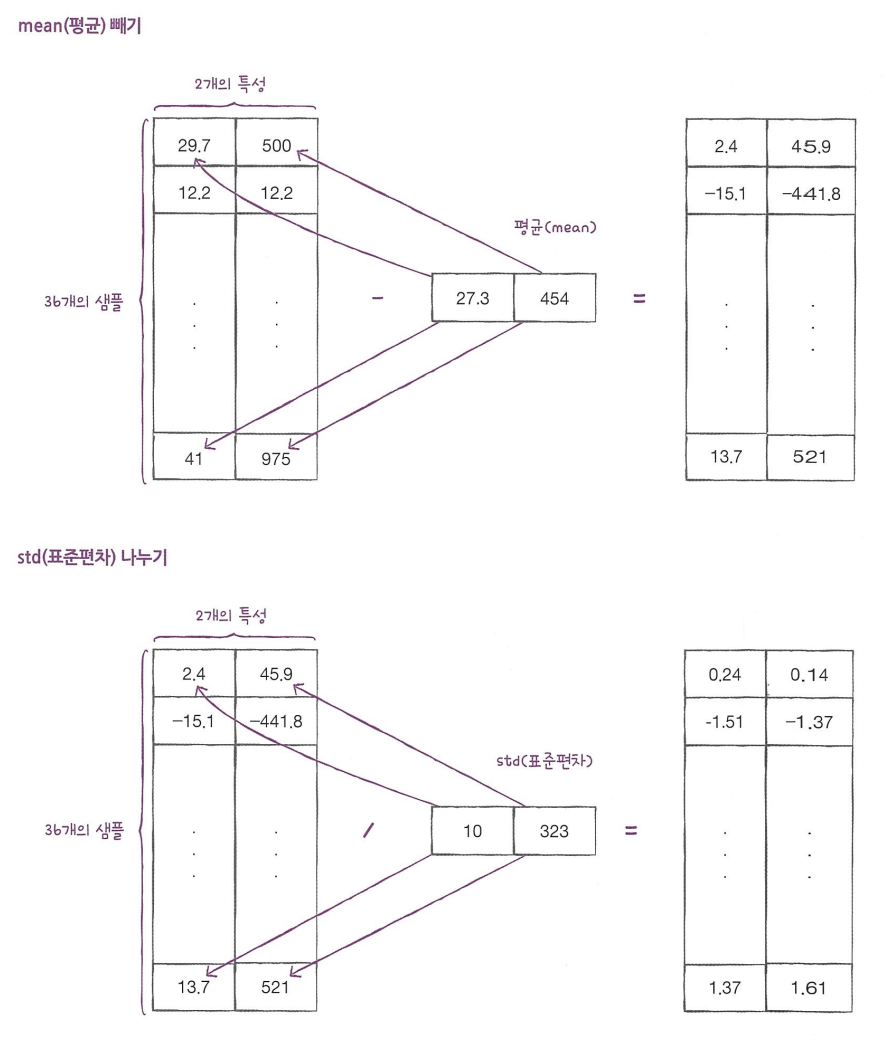
- 브로드캐스팅: 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능
표준 점수를 구하는 과정은 아래와 같다.
1
train_scaled = (train_input - mean) / std
브로드캐스팅을 이용해 표준점수를 구하고, 이를 test 하려는 sample(set)에도 적용한 뒤, 그래프로 표현하면 아래와 같다.
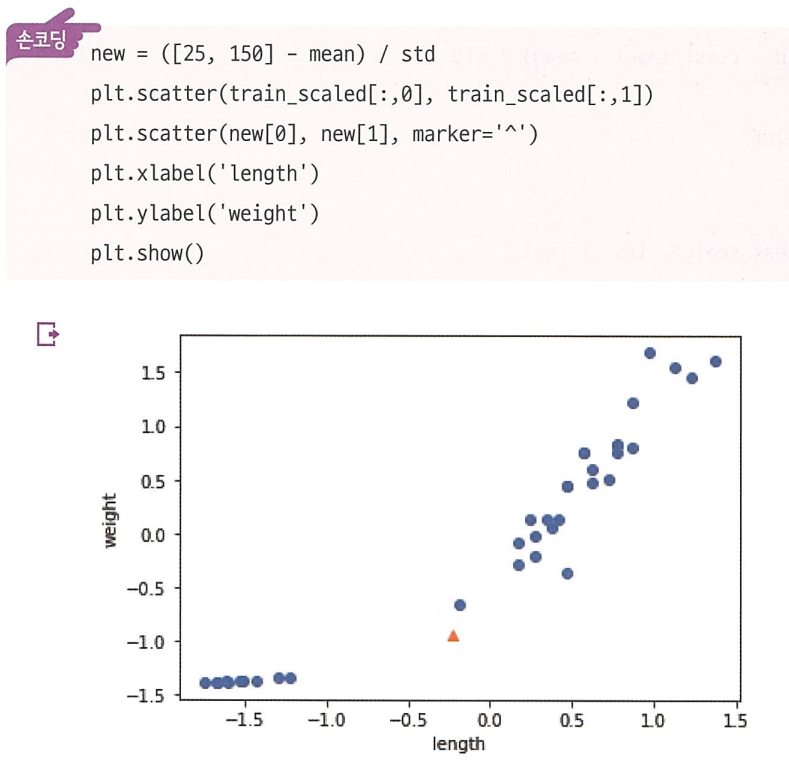
여기서 우리가 관심 있는 샘플의 최근접이웃을 그래프에 표현하면 아래와 같다.
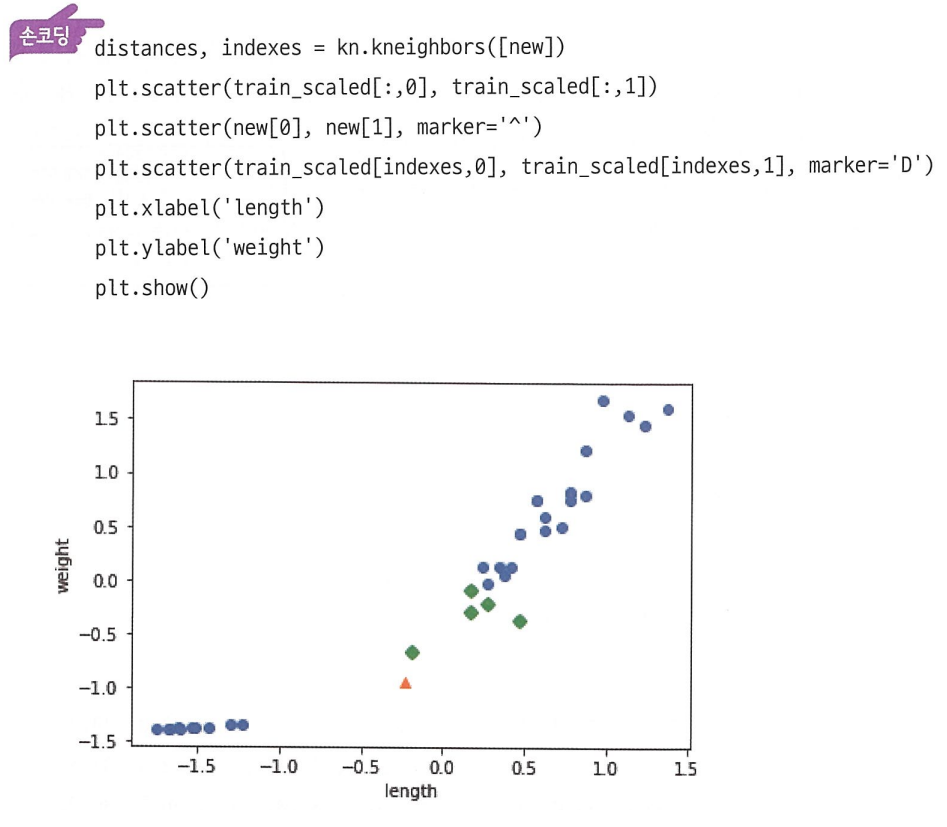
이러한 과정을 통해 스케일이 다른 특성을 적절하게 처리하여 문제 없이 k-nn 분류를 수행할 수 있다.
핵심 패키지와 함수
scikit-learn
- train_test_split(): 훈련 데이터를 훈련셋과 테스트셋으로 나누는 함수. 여러 개의 배열을 전달할 수 있다. 테스트셋으로 나눌 비율은 test_size 매개변수서 지정할 수 있고, 기본값은 0.25다. shuffle 매개변수로 훈련셋과 테스트셋으로 나누기 전에 무작위로 섞을지 여부를 결정할 수 있고 기본값은 True다. stratify 매개변수에 클래스 레이블이 담긴 배열을 전달하면 클래스 비율에 맞게 훈련셋과 테스트셋을 나눈다.
- kneighbors(): k-nn 객체의 method. 이 method는 입력한 데이터와 가장 가까운 이웃을 찾아서 거리와 이웃 샘플의 인덱스를 반환한다. 기본적으로 이웃의 개수는 KNeighborsClassifier 클래스의 객체를 생성할 때 지정한 개수를 사용한다. 하지만 n_neighbors 매개변수에서 다르게 지정할 수도 있다. return_distance 매개변수의 기본값은 True지만, False로 지정하면 이웃 샘플의 인덱스만 반환하고 거리는 반환하지 않는다.
세션 복습
발표 내용 복습
zip(): 나열된 리스트에서 원소를 하나씩 꺼내주는 역할from ~ import : 패키지나 모듈 전체를 import하지 않고 특정 클래스만 import하기 위해 사용
맨해튼 거리 vs. 유클리드 거리:
지도(supevised) 학습 vs. 비지도(unsupervised) 학습
- supervised: 입력과 타깃으로 이뤄진 훈련 데이터가 필요하다. labeled observation, 즉 이미 라벨링된, 정답이 있는 데이터들을 가진다.
unsupervised: 타깃 없이 입력 데이터만 사용, 무엇을 예측하는게 아니라 데이터 자체에서 어떠한 특징이나 패턴을 찾는데 주로 활용한다.
- supervised learning과 unsupervised learning의 가장 큰 차이점은 학습 시 정답(Label)의 제공 여부다
More about unsupervised learning
- 군집화(Clustering) ex. K-means
- 연관 규칙 학습(Association Rule Discovery) ex. 장바구니 분석
- 차원 축소: 데이터의 feature 수를 줄이면서 중요한 정보를 보존함. 다시 말해 고차원의 데이터를 저차원으로 만드는 것. ex. 주성분 분석(PCA)
위의 사진에서 30도 가량 기울어진 방향의 축을 새로운 x축으로 설정하고 2차원 데이터를 1차원으로 축소한다. 차원 축소는 단순히 데이터의 차원을 줄인다는 점에서 데이터 전처리로 생각할 수 있으나, 그 과정에서 군집 구조 파악 등에 도움을 줄 수 있기에 단순 전처리를 넘어, unsupervised learning의 일종으로 본다.
데이터가 클수록 파이썬의 리스트는 비효율적이므로 numpy의 array를 쓰는게 좋다 –> (list는 다른 객체를 가리키는 포인터가 포함되기에 더 많은 용량을 차지하고 개별 객체로 저장하기에 연산에도 더 오랜 시간이 걸린다. array는 연속적인 메모리에 저장되어 더 적은 메모리를 차지하고 벡터화 연산을 통해 성능을 극대화 할 수 있다.)
표준점수(standard score) = z score
About. Machine Learning
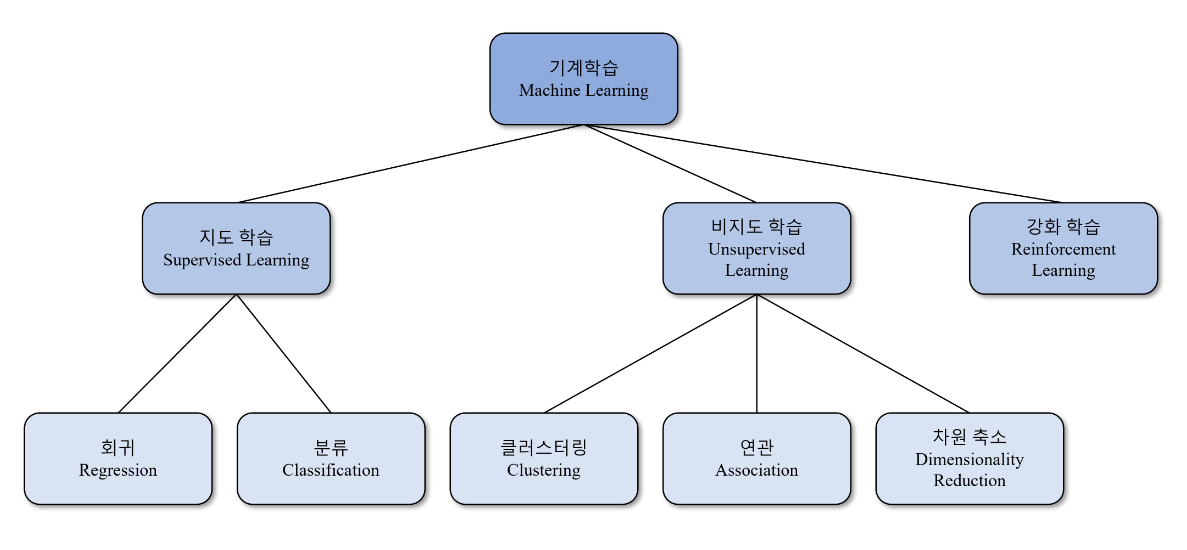
회귀 분석: 주어진 데이터들을 바탕으로 회귀선을 찾아내고 그 회귀선에 기반하여 새로운 데이터에 대한 정답을 찾아내는 것이다. 분류(Classification)와 비교되는 점은, 분류는 데이터와 정답이 제공될 때 그 정답이 클래스이기에 어느곳으로 갈지 분류할 수 있는 것이고, 회귀는 이 정답을 수치형의 데이터로 제공하기에 어떤 수치가 결과로 나올지 예측할 수 있는 것이다. +일반적으로 회귀모델을 예측모델이라고 지칭한다.
Q&A복습
1.모델을 훈련시킬때 [[1,2],[2,3],[3,4]]이런 형식의배열을
[[1,2]
[2,3]
[3,4]] 이런 형식의 2차원 배열로 변환 시키는 이유가 궁금합니다.
→ 내 생각: 사이킷런이 numpy의 array형식(2차원 배열)을 입력으로 받기 때문에
- A. 효율성을 높이기 위해서 / 백터
2. train_test_split()함수는 기본적으로 25%의 테스트 세트를 떼어낸다고 했는데 도미&빙어 문제에서 49개 샘플 중 12개가 아닌 13개가 테스트 세트로 떼어진 이유가 궁금합니다.
- A. 아마 올림 처리 되도록 설정되어있는게 아닐까..!
3. 표준점수를 이용하여 데이터 전처리를 할 때의 단점은 없나요? 만약 있다면 이 단점을 보완하기 위하여 어떤 방법들이 사용되나요?
- A. 평균은 극단적인 값의 영향을 많이 받는다. 때문에 상하위 일정 %를 제거하는 등 이를 보완하기 위한 방법들이 존재한다.
4. 최적의 K-NN모델을 구하기 위해서 이웃의 숫자를 일일이 바꾸어가며 모델을 비교하지 않고 최적의 모델을 한 번에 구할 수 있는 방법이 있는지 궁금합니다.
- A. 반복문을 이용한 코딩
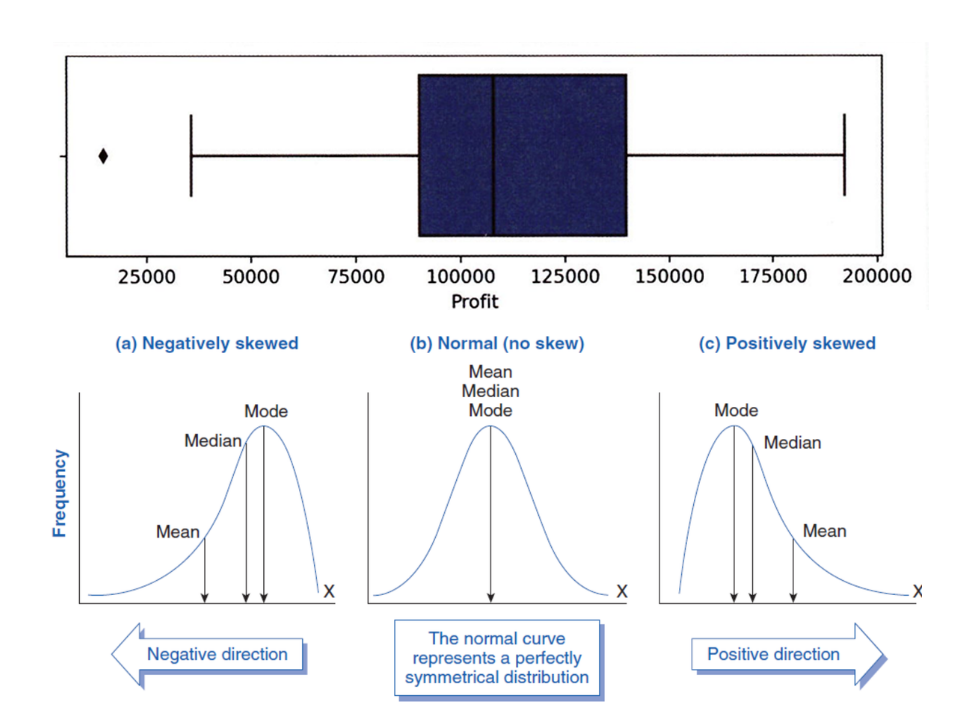
5. 데분알 10.8의 박스 플롯 그림을 ‘오른쪽으로 치우친 분포’라고 교과서에서 설명했습니다. 상식적으로는 평균 이하의 데이터 수가 많으니까 왼쪽으고 치우친 분포라고 생각했는데 왜도(skewness) 개념을 적용하여 중간값<평균값의 분포의 경우 Positive Skewness이기 때문에 오른쪽으로 치우친 분포라 설명한건가요??
- A. 중간값 < 평균값이라 positive skewness, 꼬리를 보고 오른쪽으로 치우쳐져 있다고 한다.